
We have looked at what we mean by cloud-native in an earlier post here. Recently we also looked at edge-native infrastructure here. While we have been debating between cloud and edge for a while, in a new presentation (embedded below), Gorkem Yigit, Principal Analyst, Analysys Mason argues that the new, distributed IT/OT applications will drive the shift from cloud-native to edge-native infrastrcuture.
The talk by Gorkem on '5G and edge network clouds: industry progress and the shape of the new market' from Layer123 World Congress 2021 is as follows:
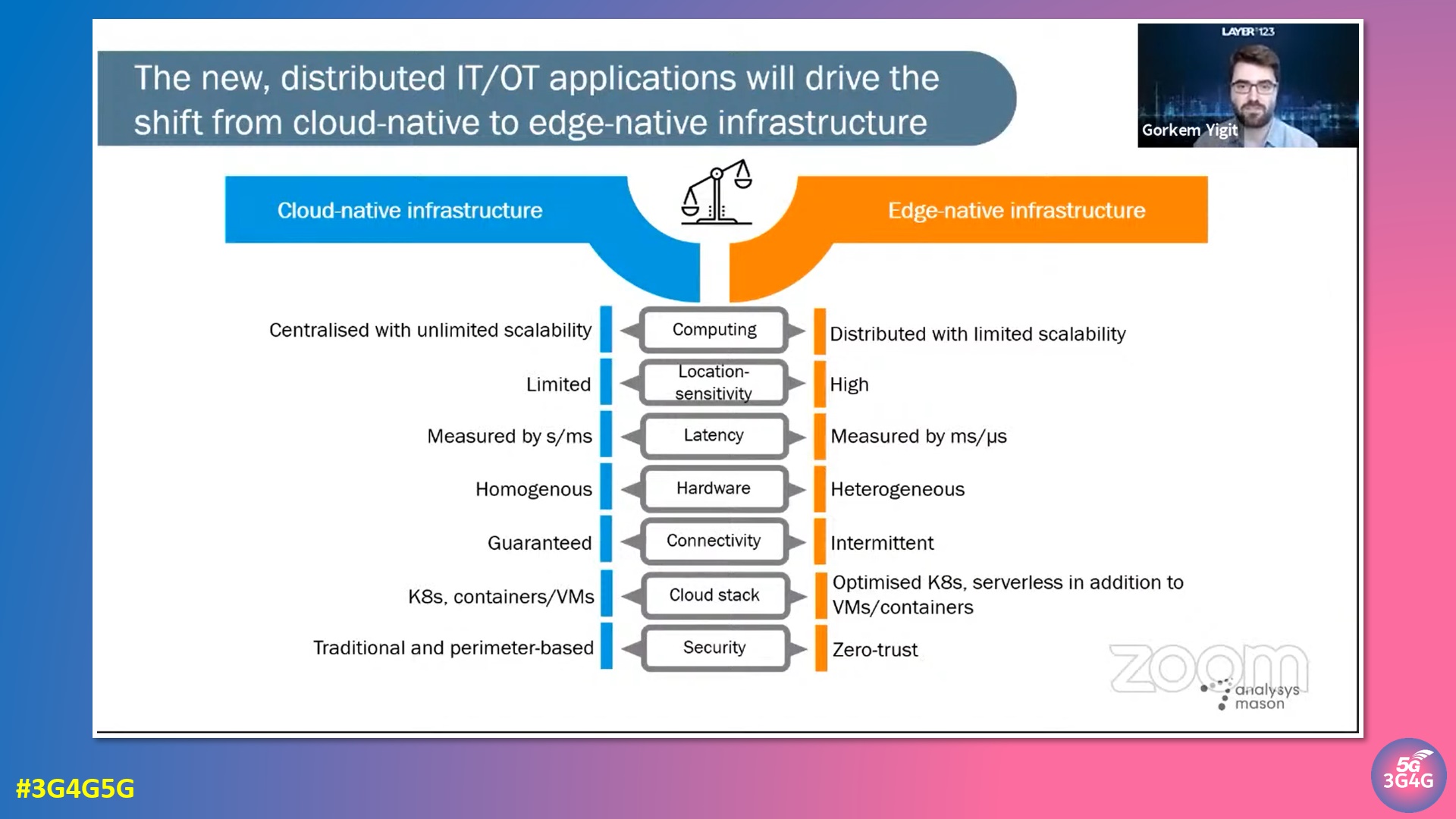
A blog post by ADVA has a nice short summary of the image on the top that was also presented at a webinar earlier. The following is an extract from that blog post:
The diagram compares hyperscale (“cloud-native infrastructure”) on the left with hyper-localized (“edge-native infrastructure”) on the right.
- Computing: The traditional hyperscale cloud is built on centralized and pooled resources. This approach enables unlimited scalability. In contrast, compute at the edge has limited scalability, and may require additional equipment to grow applications. But the initial cost at the edge is correspondingly low, and grows linearly with demand. That compares favorably to the initial cost for a hyperscale data center, which may be tens of millions of dollars.
- Location sensitivity and latency: Users of the hyperscale data center assume their workloads can run anywhere, and latency is not a major consideration. In contrast, hyper-localized applications are tied to a particular location. This might be due to new laws and regulations on data sovereignty that require that information doesn’t leave the premises or country. Or it could be due to latency restrictions as with 5G infrastructure. In either case, shipping data to a remote hyperscale data center is not acceptable.
- Hardware: Modern hyperscale data centers are filled with row after row of server racks – all identical. That ensures good prices from bulk purchases, as well as minimal inventory requirements for replacements. The hyper-localized model is more complicated. Each location must be right-sized, and supply-chain considerations come into play for international deployments. There also may be a menagerie of devices to manage.
- Connectivity: Efficient use of hyperscale data centers depends on reliable and high-bandwidth connectivity. That is not available for some applications. Or they may be required to operate when connectivity is lost. An interesting example of this case is data processing in space, where connectivity is slow and intermittent.
- Cloud stack: Hyperscale and hyper-localized deployments can host VMs and containers. In addition, hyper-localized edge clouds can host serverless applications, which are ideal for small workloads.
- Security: Hyperscale data centers use a traditional perimeter-based security model. Once you are in, you are in. Hyper-localized deployments can provide a zero-trust model. Each site is secured as with a hyperscale model, but each application can also be secured based on specific users and credentials.
You don’t have to choose upfront
So, which do you pick? Hyperscale or hyper-localized?
The good news is that you can use both as needed, if you make some good design choices.
- Cloud-native: You should design for cloud-native portability. That means using technologies such as containers and a micro-services architecture.
- Cloud provider supported edge clouds: Hyperscale cloud providers are now supporting local deployments. These tools enable users to move workloads to different sites based on the criteria discussed above. Examples include IBM Cloud Satellite, Amazon Outposts, Google Anthos, Azure Stack and Azure Arc.
Related Posts:
- The 3G4G Blog: What is Cloud Native and How is it Transforming the Networks?
- The 3G4G Blog: Realizing Zero Trust Architecture for 5G Networks
- The 3G4G Blog: Edge Computing Tutorial from Transforma Insights
- The 3G4G Blog: 3GPP Standards on Edge Computing
- The 3G4G Blog: Edge Computing - Industry Vertical Viewpoints
- The 3G4G Blog: Webinar: Where Edge Meets Cloud by Dean Bubley
- Telecoms Infrastructure Blog: AWS for Public and Private 5G Networks
- Telecoms Infrastructure Blog: SK Telecom’s 5G MEC Status and Plan
- Telecoms Infrastructure Blog: Operator Cloud Infrastructure and Innovation Strategy
- Operator Watch Blog: How is KT Reducing the Latency of their 5G Network

1 comment:
Thanks for sharing this informative article on Transitioning from Cloud-native to Edge-Native Infrastructure in detail. If you have any requirement to Hire Azure Cloud services for your business. Please visit us.
Post a Comment